
很多人用过 RAG 后会问一个问题:为什么检索结果总是”差点意思”?
明明问的是”2024 年后入职的远程员工年假政策”,系统却返回了一堆包含”年假""远程""员工”但完全对不上问题的文档。
这背后的根本原因是:传统 RAG 骨子里是被动的——你问什么,它就字面意思去找什么,不会理解你真正想要什么。
而 Agentic RAG(智能体增强的 RAG)正在改变这个局面。
传统 RAG 的三个硬伤
在说 Agentic RAG 之前,先把传统方案的局限说清楚:
1. 不会理解真正的问题
你问:“公司对去年以来入职的异地办公员工有什么调休规定?”
文档里可能写的是”远程协作人员""入职满一年者""休息制度”。词对不上,传统检索就哑火了。
这不是搜索算法的问题,而是系统根本不知道”异地办公员工”和”远程协作人员”是同一类人。
2. 一次检索打天下
无论问题多复杂,传统 RAG 都只会生成一个搜索query去查。但复杂问题往往需要多步检索、多次推理,单次查询很难覆盖全面。
3. 不管不顾地堆材料
假设你有一万页文档,模型上下文只有 128k token,传统 RAG 可能一股脑把所有”有点相关”的内容都塞进去。结果有效信息被淹没,回答质量反而下降。
Agentic RAG 是怎么工作的
如果说传统 RAG 是一个听话但不太动脑子的助理,那 Agentic RAG 更像一个会主动思考的专家。
它的核心变化是把 AI 智能体(Agent)嵌入了检索流程的每个关键节点,让系统能够:
- 理解真实意图:不只是匹配关键词,而是理解用户到底想知道什么
- 规划检索策略:判断需要查什么、怎么查、查几轮
- 执行多步检索:把复杂问题拆成多个子问题,并行或串行检索
- 整合并验证结果:把多轮检索结果汇总,追踪引用来源

一个生活化的比喻
想象你去医院看病。
传统 RAG 的做法:你告诉护士”我头疼”,护士就翻出一本《常见病症大全》,把所有提到”头疼”的章节都复印给你,让你回去自己看。
Agentic RAG 的做法:护士先问你是怎么疼、疼了多久、还有什么其他症状,然后判断你可能需要看内科还是神经科,帮你挂好号、预约检查,再把医生诊断和检查报告汇总成一份清晰的病历。
区别在哪里?后者不是机械地执行指令,而是理解目标、规划步骤、主动推进。
具体来看:Agentic RAG 的四大核心能力
1. 智能查询分解
面对”公司对 2023 年后入职的远程员工的报销政策有什么更新”这样的问题,Agentic RAG 会自动把它拆成几个子查询:
- “远程员工报销政策”
- “2023 年后入职员工规定”
- “公司报销政策最新更新”
这些子查询可以并行执行,然后合并结果,Coverage(覆盖率)远高于单个查询。
2. 多知识源并行访问
企业数据往往分散在多个地方:SharePoint 存制度文档、数据库存报销记录、内部 Wiki 存流程说明。Agentic RAG 可以同时向多个数据源发起查询,而不需要提前把所有数据汇聚到一个地方。
3. 追踪引用来源
每条检索结果都附带”这条信息来自哪份文件的哪一段”,最终回答也标注清楚引用来源。这对需要严谨依据的企业场景(比如法务、合规)非常重要。
4. 自适应的检索策略
系统会根据问题复杂度调整策略。简单事实型问题走轻量快速路径;需要推理的复杂问题则触发多步检索和深度分析。
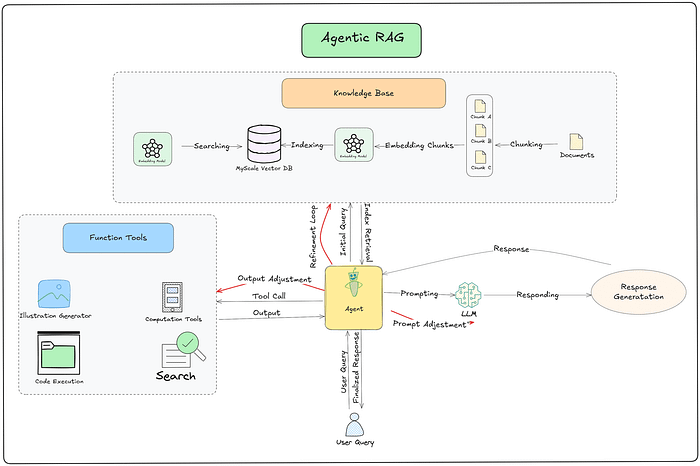
和传统 RAG 的对比
| 维度 | 传统 RAG | Agentic RAG |
|---|---|---|
| 查询方式 | 单次查询,原样匹配 | 智能分解,多步规划 |
| 数据源 | 通常一个索引 | 多源并行查询 |
| 结果呈现 | 原始文档片段 | 结构化答案 + 引用来源 |
| 复杂问题处理 | 弱 | 强(多跳推理) |
| 上下文利用 | 容易堆砌噪声 | 精准召回,按需组织 |
现在用在哪里
Agentic RAG 目前主要落地在以下几类场景:
- 企业知识库问答:员工问 HR 问题,系统自动判断查哪个知识源、怎么组合答案
- 法律/合规文档分析:需要跨多个文档理解条款,并给出有出处的结论
- 技术支持智能体:用户描述一个问题,系统逐步排查、多次检索相关文档,定位原因
- 复杂研究报告:需要综合多篇论文、多方数据源形成结论
值得注意的现状
Agentic RAG 技术很热,但还在快速迭代阶段。大多数企业级方案(如 Azure AI Search 的 Agentic Retrieval)仍处于预览版(Preview),生产环境使用需要评估稳定性。
另外,Agentic RAG 因为多了 LLM 做查询规划和结果整合,延迟和成本会比传统 RAG 更高。不是所有场景都需要这套方案——简单的事实问答用传统 RAG 足够高效。
一句话总结
Agentic RAG 的本质是把”规划”能力引入检索流程:不再是你问什么系统就找什么,而是系统先理解你要什么,再决定怎么找、找什么、找几轮。
如果说传统 RAG 是一把好用的检索工具,那 Agentic RAG 更像一个会主动思考的助手——代价更大,但能力边界也宽得多。
原文链接:https://medium.com/@myscale/a-beginners-guide-on-agentic-rag-f1254d836063